1. linux常见查找命令
1.1. which
从文档可以看出:which命令的作用是,在PATH变量指定的路径中,搜索某个系统命令的位置,并且返回第一个搜索结果。也就是说,使用which命令,就可以看到某个系统命令是否存在,以及执行的到底是哪一个位置的命令。
参数信息:
-n<文件名长度>:制定文件名长度,指定的长度必须大于或等于所有文件中最长的文件名;
-p<文件名长度>:与-n参数相同,但此处的<文件名长度>包含了文件的路径;
-w:指定输出时栏位的宽度;
-V:显示版本信息。
1.2. whereis
从文档可以看出:whereis命令只能用于程序名的搜索,
参数信息:
-b:只查找二进制文件;
-B<目录>:只在设置的目录下查找二进制文件;
-f:不显示文件名前的路径名称;
-m:只查找说明文件;
-M<目录>:只在设置的目录下查找说明文件;
-s:只查找原始代码文件;
-S<目录>只在设置的目录下查找原始代码文件;
-u:查找不包含指定类型的文件。
如果省略参数,则返回所有信息。
例: whereis ls 和 whereis grep
1.3. whatis
whatis命令是用于查询一个命令执行什么功能,并将查询结果打印到终端上
whatis 命令相当于 man -f 命令
whatis cp whatis grep whatis chown whatis man
1.4. locate
yum -y install mlocate updatedb
locate命令和slocate命令都用来查找文件或目录。
用法:locate/slocate (选项)参数
locate命令其实是find -name的另一种写法,但是locate要比后者快得多,原因在于它不搜索具体目录,而是搜索一个数据库/var/lib/locatedb,这个数据库中含有本地所有文件信息。
1.5. find
find命令用来在指定目录下查找文件。
任何位于参数之前的字符串都将被视为欲查找的目录名。如果使用该命令时,不设置任何参数,则find命令将在当前目录下查找子目录与文件。并且将查找到的子目录和文件全部进行显示。
1.5.1. 使用格式
find <指定目录><指定条件><指定动作>
- <指定目录>: 所要搜索的目录及其所有子目录。默认为当前目录。
- <指定条件>: 所要搜索的文件的特征。
- <指定动作>: 对搜索结果进行特定的处理。
1.5.2. 参数选项
find命令是最常见和强大的查找命令,用它可以找到任何你想查找的内容。因此它的参数也是非常多的。
大概可以归类为以下几种:
1.根据文件或正则表达式进行匹配。
2.根据时间查找。
3.根据文件权限(所属组,拥有者)查找。
4.借助-exec与其他命令结合使用。
1.6. type
type命令用来显示指定命令的类型,判断给出的指令是内部指令还是外部指令
1.7. ldd
ldd用来查看程序运行所需的共享库,常用来解决程序因缺少某个库文件而不能运行的一些问题
1.8. awk & sed & grep
sed 编辑, awk 根据内容分析并处理, grep 查找.
- awk(关键字:分析&处理) 一行一行的分析处理 awk ‘条件类型1{动作1}条件类型2{动作2}’ filename, awk 也可以读取来自前一个指令的 standard input 相对于sed常常用于一整行处理, awk则比较倾向于一行当中分成数个”字段”(区域)来处理, 默认的分隔符是空格键或tab键
例如: last -n 5 | awk ‘{print $1 “\t” $3}’ 这里大括号内$1”\t”$3 之间不加空格也可以, 不过最好还是加上个空格, 另外注意”\t”是有双引号的, 因为本身这些内容都在单引号内 $0 代表整行 $1代表第一个区域, 依此类推 awk的处理流程是:
- 读第一行, 将第一行资料填入变量 $0, $1… 等变量中
- 依据条件限制, 执行动作
- 接下来执行下一行 所以, AWK一次处理是一行, 而一次中处理的最小单位是一个区域 另外还有3个变量, NF: 每一行处理的字段数, NR 目前处理到第几行 FS 目前的分隔符 逻辑判断 > < >= <= == !== , 赋值直接使用= cat /etc/passwd | awk ‘{FS=”:”} $3<10 {print $1 “\t” $3}’ 首先定义分隔符为:, 然后判断, 注意看, 判断没有写在{}中, 然后执行动作, FS=”:”这是一个动作, 赋值动作, 不是一个判断, 所以不写在{}中 BEGIN END , 给程序员一个初始化和收尾的工作, BEGIN之后列出的操作在{}内将在awk开始扫描输入之前执行, 而END{}内的操作, 将在扫描完输入文件后执行. awk ‘/test/ {print NR}’ abc 将带有test的行的行号打印出来, 注意//之间可以使用正则表达式 awk {}内, 可以使用 if else ,for(i=0;i<10;i++), i=1 while(i<NF) 可见, awk的很多用法都等同于C语言, 比如”\t” 分隔符, print的格式, if, while, for 等等
- sed(关键字: 编辑) 以行为单位的文本编辑工具 sed可以直接修改档案, 不过一般不推荐这么做, 可以分析 standard input
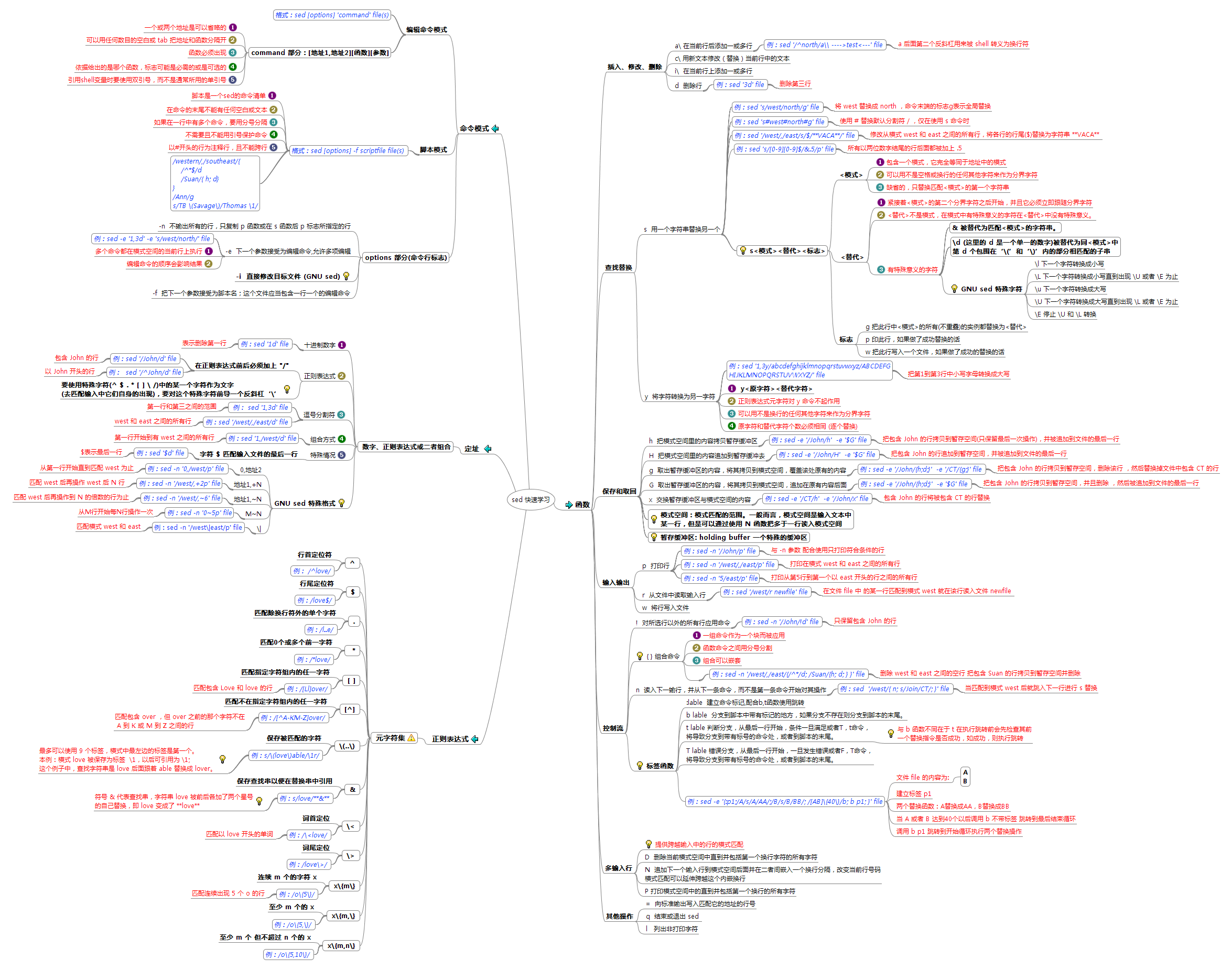
基本工作方式: sed [-nef] ‘[动作]’ [输入文本]
-n : 安静模式, 一般sed用法中, 来自stdin的数据一般会被列出到屏幕上, 如果使用-n参数后, 只有经过sed处理的那一行被列出来.
-e : 多重编辑, 比如你同时又想删除某行, 又想改变其他行, 那么可以用 sed -e ‘1,5d’ -e ‘s/abc/xxx/g’ filename
-f : 首先将 sed的动作写在一个档案内, 然后通过 sed -f scriptfile 就可以直接执行 scriptfile 内的sed动作 (没有实验成功, 不推荐使用)
-i : 直接编辑, 这回就是真的改变文件中的内容了, 别的都只是改变显示. (不推荐使用)
动作:
a 新增, a 后面可以接字符串, 而这个字符串会在新的一行出现. (下一行)
c 取代, c 后面的字符串, 这些字符串可以取代 n1,n2之间的行
d 删除, 后面不接任何东西
i 插入, 后面的字符串, 会在上一行出现
p 打印, 将选择的资料列出, 通常和 sed -n 一起运作 sed -n ‘3p’ 只打印第3行
s 取代, 类似vi中的取代, 1,20s/old/new/g
[line-address]q 退出, 匹配到某行退出, 提高效率
[line-address]r 匹配到的行读取某文件 例如: sed ‘1r qqq’ abc , 注意, 写入的文本是写在了第1行的后边, 也就是第2行
[line-address]w file, 匹配到的行写入某文件 例如: sed -n ‘/m/w qqq’ abc , 从abc中读取带m的行写到qqq文件中, 注意, 这个写入带有覆盖性.
举例:
sed '1d' abc 删除 abc 档案里的第一行, 注意, 这时会显示除了第一行之外的所有行, 因为第一行已经被删除了(实际文件并没有被删除,而只是显示的时候被删除了)
sed -n '1d' abc 什么内容也不显示, 因为经过sed处理的行, 是个删除操作, 所以不现实.
sed '2,$d' abc 删除abc中从第二行到最后一行所有的内容, 注意, $符号正则表达式中表示行末尾, 但是这里并没有说那行末尾, 就会指最后一行末尾, ^开头, 如果没有指定哪行开头, 那么就是第一行开头
sed '$d' abc 只删除了最后一行, 因为并没有指定是那行末尾, 就认为是最后一行末尾
sed '/test/d' abc 文件中所有带 test 的行, 全部删除
sed '/test/a RRRRRRR' abc 将 RRRRRRR 追加到所有的带 test 行的下一行 也有可能通过行
sed '1,5c RRRRRRR' abc
sed '/test/c RRRRRRR' abc 将 RRRRRRR 替换所有带 test 的行, 当然, 这里也可以是通过行来进行替换, 比如 sed '1,5c RRRRRRR' abc
- grep(关键字: 截取) 文本搜集工具, 结合正则表达式非常强大
主要参数 []
-c : 只输出匹配的行
-i : 不区分大小写
-h : 查询多文件时不显示文件名
-l : 查询多文件时, 只输出包含匹配字符的文件名
-n : 显示匹配的行号及行
-v : 显示不包含匹配文本的所有行(我经常用除去grep本身)
-E : 使用正则表达式
基本工作方式: grep 要匹配的内容 文件名, 例如:
grep "test" d* 显示所有以d开头的文件中包含test的行
grep "test" aa bb cc 显示在 aa bb cc 文件中包含test的行
grep "[a-z]\{5}\" aa 显示所有包含字符串至少有5个连续小写字母的串
grep -i -E "error|fail|false|fault" ./log/gogs* 查找gogs错误信息
1 多个关键字查找
1.1 使用-e
grep -e 'stdio\.h' -e 'stdlib\.h' /usr/include/*.h
1.2 使用-f file
将关键字以行方式保存在一个文件中
1.3 使用元字符 \|
grep 'stdio\.h\|stdlib.h' /usr/include/*.h
1.4 多关键字 and 查找
grep 'stdio\.h\|stdlib.h' /usr/include/*.h
2. 单词匹配
-w(gnu 选项)
grep -w 'main' /usr/include/*.h
\<\>
grep '\<main\>' /usr/include/*.h
2.善用 -E
-E选项启用 extended expression,正则写起来更加灵活
例如匹配一行内两个连续重复the或that或and或or
man gcc | grep -E '(\<the\>|\<that\>|\<and\>|\<or\>) \1'
3 多文件查找
grep -l 'main' *.c
4 忽略大小写 -i
grep -i -w 'sTAt' /usr/include/*.h
5 递归查找 -r(posix 未说明)
grep -i -w -r -E 'error|failed|failure' /var/log |less
6 显示匹配行周围行 (posix 未说明)
B/A/C(before/after/context
-B n
-A n
-C n
grep -w -i -C 3 'struct stat' /usr/include/*.h
7 取反-v
grep -v -w 'hello' filename
如果没有取反,世界将不再美丽
8 匹配数 -c
echo aaaa | grep -c 'a'
这个输出是1!因为grep是行匹配的
9 输出文件名 -l
grep -l -r -i -w 'filename_max' /usr/include/*.h
10 只输出匹配部分-o (gnu 选项)
echo abcddf |grep -o 'dd'