1. 格式化[热点]
(1) 格式化一定要使用统一的解决方案(占位符方式) 可以规避掉大多数问题.(即使是行业中水平很高的人也在这个上面栽过跟头)
(2) fmt
2. 内存
(1) 内存泄露认知 (一次性泄漏 , 常规性泄漏 , 偶发性泄漏 , 运行时泄漏)
(2) 使用内存池解决内存碎片问题, 使用对象池解决内存泄漏问题.
(3) 内存分配失败默认处理
(4) 可以用工具检测出来的内存泄漏不是内存泄露, 即我们主要要解决的内存泄漏是: 运行时泄漏
(5) gperftools
3. 日志[热点]
(1) debug不能解决所有问题, 但是日志可以.
(2) 日志的写入应该是同步的, 日志分级, 分文件.
(3) 根据项目情况选择合适的日志组件.(glog让我明白 从设计上解决问题的重要性)
(4) dmlog
4. 线程
(1) io, 操作无关, 高耗, 低锁 使用线程效率较高
(2) 设计上规避多读多写.
(3) 积极使用无锁队列.
(4) 多线程的精髓为分时 理解了分时就理解了多线程
(5) C++11 std::thread
5. 锁
注意: 锁的强度越高 效率越低, 生命周期越长 效率越低 选择合适的锁(优先选择高性能的锁)
(1) wait-free -> ringbuffer 对使用环境有要求 实现难度较大
(2) lock-free -> linux 内核中广泛应用, wait-free的算法都是lock-free的
(3) obstruction-free -> 乐观锁 -> lock-free 的算法都是obstruction-free的
(4) atomic -> std::atomic
(5) lockless-based -> std::mutex std::lock_guard
(6) lock-based -> semaphore
6. 网络[热点]
(1) 调整运行帧数为合理数值
(2) 统计协议带宽占用率
(3) 统计协议处理耗时
(4) 心跳 要自己起一个timer主动发. 防止可能的隐患.
(5) 协议 选择合适的协议 性能高->低 (二进制 > protobuf > xml) 流量低->高 (protobuf > 二进制 > xml)
(6) 网络库 asio libevent libuv libev libzmq
(7) 网络引擎性能本质点在网络事件处理单帧所耗时间
(8) 网络引擎优化要点 [1] 减少cp [2] 减少锁的粒度. [3]减少api调用次数.
7. 协议
(1) 制定统一协议标准 (2) protobuf(idl重要性) (3) luapb (动态协议导入, 静态协议导入, encode, decode, id2name, name2id, table2json, json2table, table2xml, xml2table, xml2json, json2xml, table2yaml, yaml2table)
8. 时钟
(1) 使用精度与预计精度的统一, 精度分级.
(2) 影响时钟性能的因素, 所使用的数据结构, 所使用的时间API的精度.
(3) 时钟的实现让我理解了分时, 从而在多线程问题上没有再犯过错误.
(4) dmtimer
9. db(mysql)
(1) 自动化.
(2) 逻辑简单稳定.
(3) 设置好主外键, 能明文的最好明文, 方便运维
(4) innodb [注意blob限制] myisam[有性能要求]
(5) 统一使用utf8字符集
(6) 避免使用扩展sql 方便将来移植
(7) 创意: 存储格式为xml格式 使用mysql提供的xpath API 从而解决了无尽的运维需求的问题(这里性能会有降低)
(8) dmorm
(9) dmgen4sql
10. 脚本(lua)
(1) 自动化.
(2) 功能全部由C/C++实现, 数据结构也由C/C++提供
(3) lua只负责调用, 不使用本身lua的数据结构(为了解决lua reload数据归属问题), 不实现复杂逻辑(简单原则).
(4) dmlua
11. 配置文件[热点]
(1) 自动化.
(2) 文件格式选择 使用者角度 (csv > xml > bin) 开发者角度(xml > csv > bin)
(3) dmconfig(json,csv,xml,xlsx,markdown)
12. 效率与优化
(1) 不写低效的代码, 不提前优化
(2) 不使用不成熟的优化手段
(3) 做性能评测(性能评测另一个用途是用于迅速熟悉一个新的模块或者系统) 进行热点定位
(4) 效率是一个综合的东西. 资源不对等不要比效率.
(5) 最终决定效率的是所使用的数据结构
13. 编码风格
(1) 统一标准 简单明确. 可参考google C++编码规范.
(2) 有新同事加入团队一定要安排几次review.(提升最低标准, 熟悉编码规范)
(3) 对性能有需求的地方尽量使用C风格实现.
(4) 规避使用未定义行为编码
(5) 编写有质感的代码. 当问题出现时 review时
LV1. 不知道有没有问题(无法定位问题)
LV2. 可能有问题(模糊定位问题)
LV3. 有问题(准确定位问题)
LV4. 没问题( 理想 )
14. 编码格式
(1) 想要跨平台的使用相同的代码,请使用UTF-8 with BOM编码,msvc 增加 /utf-8 选项.
15. debug的方式
(1) review [前置条件 13.4][修炼法则]
(2) debug[快速法则]
(3) log[通用法则]
16. 国际化
(1) 自动化.
(2) 使用统一的解决方案, 规避直接在代码中直接使用字符串明文.
(3) dmgen4error
17. 单元测试
(1) 构建单元测试(gtest)
(2) dmgen4gtest
18. 第三方库
(1) 选择 稳定 熟悉的库
(2) 选择更新频率较低的库
(3) 对先进的解决方案做二次封装, 减少维护成本.(造轮子的过程中心得)
19. 数据类型
(1) 尽量规避浮点数的使用
(2) 优先使用符号数, 例(int32, uint32 优先使用int32)
(3) 使用可预测数据类型,例(uint8, uint16, uint32, uint64)
20. C++学习历程
-
C++ 学习曲线:
LEVEL1 C++ 不好(内容太多)
LEVEL2 C++ 好(使用方便)
LEVEL3 C++ 不好(细节太多 容易出错)
LEVEL4 C++ 好(掌握细节)
LEVEL5 C++ 不好(效率太差)
LEVEL6 C++ 好(选择性的使用)
LEVEL7 C++ 不好(C的回归) -
C++ 学习路径:
Level 1: C++ 初学者 评判标准: 了解 C++ 基本语法,能够编写简单的程序,例如控制台输出、变量使用、简单运算等。 用例: 编写简单的 “Hello World” 程序,进行基础的数值计算。 Level 2: C++ 熟练者 评判标准: 掌握 C++ 核心语法,熟悉常用数据结构和算法,能够编写结构化的程序,例如分支、循环、函数等。 用例: 实现简单的排序算法,编写学生管理系统等小型程序。 Level 3: C++ 应用者 评判标准: 理解面向对象编程 (OOP) 的概念,能够使用类、继承、多态等特性,编写面向对象的程序。 用例: 设计并实现简单的游戏,开发图形界面应用程序。 Level 4: C++ 专家 评判标准: 掌握 C++ 高级特性,例如模板、异常处理、运算符重载等,能够编写高质量、可复用的代码。 用例: 开发高性能库或框架,设计并实现复杂的数据结构和算法。 Level 5: C++ 大师 评判标准: 深入理解 C++ 内存管理机制,能够进行底层优化,编写高性能、高效的代码。 用例: 开发实时系统、高并发应用,对现有代码进行性能分析和优化。 Level 6: C++ 架构师 评判标准: 能够根据需求选择合适的 C++ 特性,设计并实现大型软件架构,并能进行跨平台开发。 用例: 设计并实现分布式系统、云平台等复杂软件项目。 Level 7: C++ 悟道者 评判标准: 对 C++ 有着深刻的理解,洞悉其设计哲学和发展历程。 能够灵活运用 C++ 和 C,根据项目需求选择最佳方案。 积极参与 C++ 社区,推动 C++ 语言的发展。 用例: 编写高性能、可移植的库或框架。 参与 C++ 标准制定或开源项目贡献。 指导和培养下一代 C++ 开发者。 - C++ 学习方式: 自学: 通过书籍、在线课程、教程等资源进行自主学习。 学校教育: 在大学或培训机构接受系统性的 C++ 教育。 实践项目: 通过参与实际项目,在实践中学习和提升 C++ 技能。 社区交流: 加入 C++ 社区,与其他开发者交流学习经验,互相帮助。
- C++ 学习内容: 语言基础: 语法、数据类型、运算符、控制流等。 标准库 (STL): 容器、算法、迭代器等。 面向对象编程 (OOP): 类、继承、多态、封装等。 模板: 函数模板、类模板、模板元编程等。 内存管理: 指针、动态内存分配、智能指针等。 异常处理: try-catch-throw 机制,异常安全等。 并发编程: 线程、互斥锁、原子操作等。 网络编程: Socket 编程、网络协议等。 图形界面编程: 使用 Qt、wxWidgets 等库进行图形界面开发。
- C++ 学习目标: 兴趣爱好: 出于对编程的热爱,想要学习 C++ 并探索其可能性。 职业发展: 希望成为 C++ 开发工程师,从事相关领域的软件开发工作。 学术研究: 进行 C++ 相关的学术研究,例如编译器开发、语言设计等。
- C++ 学习挑战: C++ 语言本身的复杂性: C++ 语法庞大,特性繁多,学习曲线陡峭。 内存管理的难度: 手动管理内存容易出错,需要开发者具备较强的责任心和调试能力。 新标准的不断更新: C++ 标准不断演进,开发者需要持续学习新特性。
- C++ 学习建议: 循序渐进,打好基础: 从基础语法开始,逐步深入学习 C++ 的各个方面。 多实践,多练习: 将所学知识应用到实际项目中,通过实践来巩固和提升技能。 阅读优秀的 C++ 代码: 学习其他开发者优秀的代码风格和设计模式。 积极参与 C++ 社区: 与其他开发者交流学习经验,互相帮助,共同进步。
21. 架构
(1) 简单
(2) 稳定
(3) 易排查, 易扩展
(4) 可拆解
22. 基础素养
(1) 钻研精神, 勤学善问, 有好奇心
(2) 积极向上的态度, 创造性的思维
(3) 团队协作精神
(4) 谦虚谨慎 不骄不躁 工匠精神
(5) 写出高质量的代码(稳定, 易读, 规范, 易维护, 专业)
23. 理解的角度
观察 (细节)
看 (大局)
感受 (发现规律)
洞见 (点爆发)
所谓理解就是要理解模式
24. 问题理解层级
(1) 发现问题
(2) 解决问题
(3) 规避问题
(4) 消灭问题
(5) 创造问题
25. 问题规避原则
(1) 设计上规避(例如: glog在设计上面使用多线程独立文件来规避单文件加锁问题)
(2) 约定规避(例如: 约定使用int64放大若干倍数来替代浮点数)
(3) 实现规避(例如: 在高性能要求的场景, 使用纯C的数据结构来替代复杂的C++数据结构)
(4) 潜规则规避(例如: 利用平台语言或者数据结构的特性 来规避问题)
26. 如何消灭问题
(1) 编码规范
(2) 数据驱动开发
(3) 代码生成技术
(4) 为什么消灭了问题? 人是最不可控的, 减少了人本身对事物的影响.
27. 是否需要学习多种语言
理解 “在一种语言上编程” 和 “深入一种语言编程” 的区别(惯用法则)
28. 编程方法论
28.1. 防御式编程
28.2. 契约式编程
29. C++注意事项
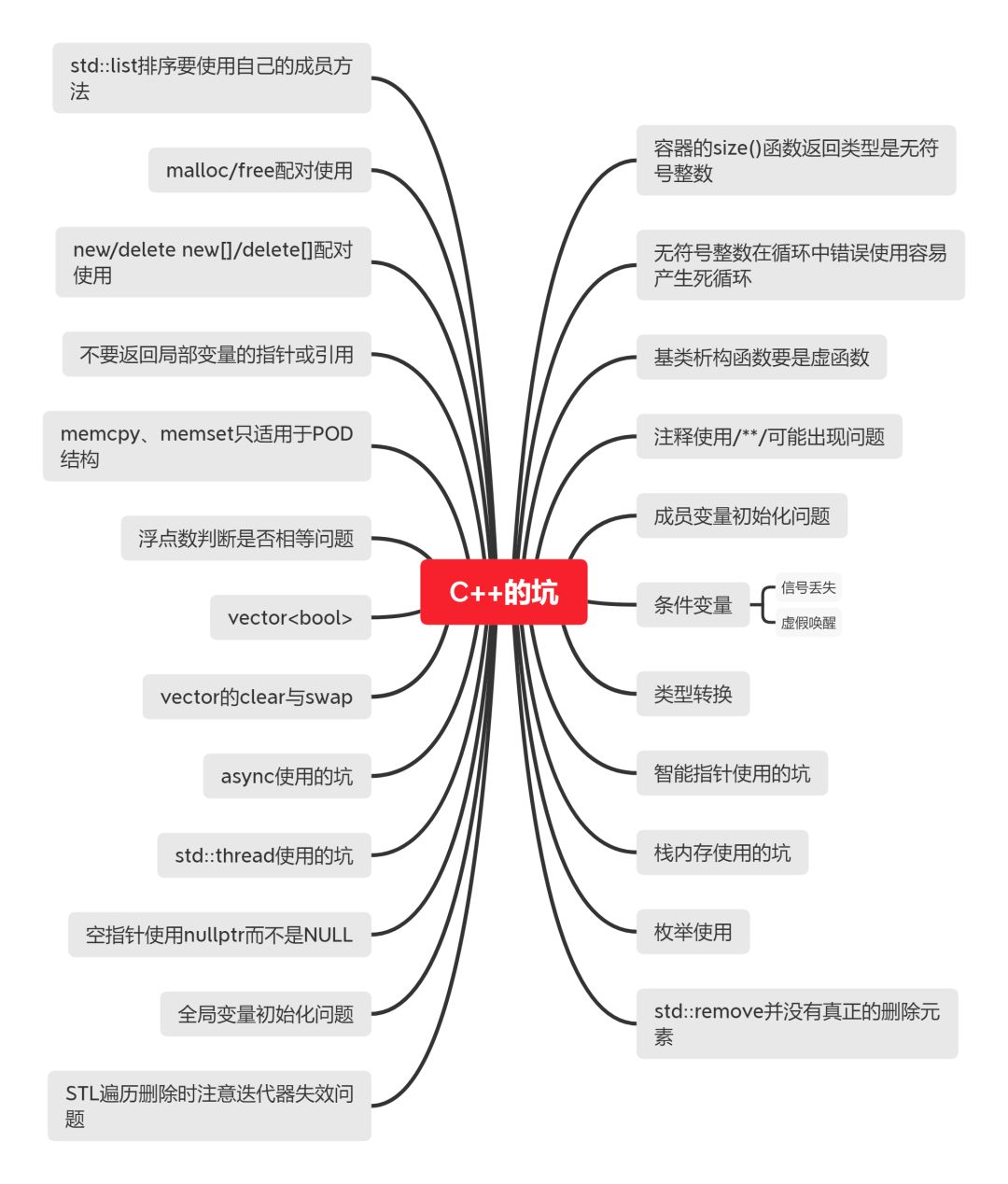
30. 编程感悟
程序的精髓在于数据结构的组织与控制.
稳定的需求是产品质量的基石.
真正的需求,潜藏在人性因素与其他一系列因素的相互关联之中.
31. 常用书籍
https://github.com/brinkqiang/dmdoc
32. 开源定制库
32.1. 模块化定制版 dump文件生成
https://github.com/brinkqiang/dmbreakpad
32.2. 模块化定制版 命令行参数解析析
https://github.com/brinkqiang/dmflags
32.3. 基于 iconv 编码转换 实现自动化探测编码格式 仅需指定输出编码格式
https://github.com/brinkqiang/dmiconv
32.4. 模块化定制版 curl
https://github.com/brinkqiang/dmcurl
32.5. 模块化定制版 fmtlib C++格式化库库
https://github.com/brinkqiang/dmformat
32.6. 模块化定制版 google性能分析库库
https://github.com/brinkqiang/dmgperftools
32.7. 模块化定制版 log库, 基于spdlogg
https://github.com/brinkqiang/dmlog
32.8. 模块化定制版 protobuf 支持3.7/3.14版本本
https://github.com/brinkqiang/dmprotobuf
32.9. 模块化定制版 C++ csv读写库库
https://github.com/brinkqiang/dmcsv
32.10. 模块化定制版 C++ xml读写库库
https://github.com/brinkqiang/dmxml
32.11. 模块化定制版 C++ json读写库库
https://github.com/brinkqiang/dmjson
33. 个人开源库
33.1. 高性能定时器, 支持cron表达式
https://github.com/brinkqiang/dmtimer
33.2. C++ ORM
https://github.com/brinkqiang/dmorm
33.3. C++/lua引擎 基于toluapp
https://github.com/brinkqiang/dmlua
33.4. C++/lua引擎 基于sol2 分析C++头文件实现自动化导出
https://github.com/brinkqiang/dmsolpp
33.5. C++ 错误码自动生成器器
https://github.com/brinkqiang/dmgen4error
33.6. C++ 协议派发生成器器
https://github.com/brinkqiang/dmgen4pbmsg
33.7. C++ config文件自动化生成器 支持json, xml, csv, md等格式
https://github.com/brinkqiang/dmconfig
33.8. C++ SQL语句生成器
https://github.com/brinkqiang/dmsql
33.9. C++ SQL表库自动化对比 差异SQL生成器
https://github.com/brinkqiang/dmsqldiff
33.10. C++ 协议头通用处理库
https://github.com/brinkqiang/dmmsgparser
33.11. C++ 唯一ID生成库
https://github.com/brinkqiang/dmsnowflake
C++ 开发中常见问题的复杂度、影响范围和解决难度,将其分为 1-10 级。以下是一个可能的分级方案:
您是对的,将“设计模式的灵活组合与变通应用”放在Level 9确实可能对于“理解和应用单个常见设计模式”而言过高了。设计模式本身的学习曲线可以比较平缓,但其在复杂系统中的精妙组合、权衡取舍以及针对特定问题的“变通”则非常考验经验和架构能力。
为了更准确地反映不同层次的难度,我们可以将“设计模式”的掌握拆分到不同级别:
- 基础理解和应用:了解常见模式的意图、结构和基本用法。
- 综合与高级应用:在复杂场景下组合使用模式,理解其深层影响,并能对其进行适配和创新。
让我们基于此,并对整个列表进行一次更全面的审视和调整,力求各级别内部的难度和所需经验更加一致。
调整后的C++问题难度分级方案:
Level 1 - 基础语法 & 核心STL使用
- 变量作用域、指针与引用混淆、值/指针/引用传递错误
std::vector,std::map,std::string等核心容器的错误使用(如不当的插入、访问)- 对
const正确性的忽视 - 基本的头文件管理与声明/定义分离概念不清
复杂度: 2/10 | 影响范围: 3/10 (局部bug) | 解决难度: 2/10
- 说明: C++入门最常见的绊脚石,通常导致编译错误或运行时简单崩溃。
Level 2 - 现代C++特性入门 & STL进阶
std::shared_ptr,std::unique_ptr的错误使用(如循环引用、不当释放)- STL容器迭代器失效问题(如
erase()操作后未更新迭代器) std::move,std::forward的误用或不理解其场景- 右值引用、移动语义的基本概念混淆
lambda表达式的捕获列表问题
复杂度: 3/10 | 影响范围: 4/10 (性能、资源泄漏) | 解决难度: 3/10
- 说明: 开始接触C++11及以后特性,对资源管理和性能有初步影响。
Level 3 - 面向对象设计原则 & 常见设计模式
- 类设计违反单一职责、开闭原则等
- 继承与组合的滥用,多态的错误实现
- 理解并应用常见GoF设计模式 (如 Singleton, Factory Method, Abstract Factory, Observer, Decorator, Strategy, Adapter)
std::function,std::bind的使用std::optional,std::variant等工具类的应用场景
复杂度: 4/10 | 影响范围: 5/10 (模块可维护性、扩展性) | 解决难度: 4/10
- 说明: 关注代码组织和模块化设计。正确应用设计模式能提升代码质量,但误用也会引入不必要的复杂性。
Level 4 - 线程与并发编程基础
std::thread,std::mutex,std::condition_variable的基本使用与协作- 简单数据竞争、忘记加锁/解锁导致的死锁
std::atomic变量的基本使用(如原子计数器)std::future,std::promise,std::async的基本用法与陷阱
复杂度: 5/10 | 影响范围: 7/10 (系统稳定性、数据一致性) | 解决难度: 5/10
- 说明: 并发编程的入门,问题通常难以复现和调试。
Level 5 - 内存管理 & 初级底层优化
new/delete与malloc/free的混用、内存泄漏、悬垂指针- 对齐、
padding问题导致的性能或兼容性问题 - 内存分析工具 (
Valgrind,AddressSanitizer) 的使用与报告解读 placement new的理解与特定场景应用- 自定义简单的固定大小
memory pool或arena allocator
复杂度: 6/10 | 影响范围: 6/10 (性能、稳定性) | 解决难度: 6/10
- 说明: 深入理解C++内存模型,开始尝试手动优化内存分配。
Level 6 - 网络编程与I/O模型
boost::asio(或类似库) 的异步模型理解 (io_context,strand,handler)- 同步/异步TCP & UDP通信中的常见错误 (粘包、连接管理、错误处理)
- 文件流 (
std::ifstream,std::ofstream) 的高级用法与错误处理 - 理解
select,poll,epoll(或kqueue,IOCP) 的工作原理及在C++中的应用
复杂度: 6/10 | 影响范围: 7/10 (系统吞吐量、响应性) | 解决难度: 7/10
- 说明: 涉及操作系统I/O模型,是构建高性能服务的核心。
Level 7 - C++模板元编程(TMP)与高级泛型编程
- SFINAE (
Substitution Failure Is Not An Error) 的理解与应用 constexpr if,template<auto>,variadic templates的高级技巧- CRTP(Curiously Recurring Template Pattern)的深入应用与变种
- 自定义类型萃取 (
type traits) 与std::enable_if的复杂组合 Concepts(C++20) 的设计与应用
复杂度: 8/10 | 影响范围: 6/10 (库设计、编译期优化、代码可读性) | 解决难度: 7/10
- 说明: 利用编译器在编译期进行计算和代码生成,编写高度通用和高效的库,但调试和理解难度大。
Level 8 - 高级并发与底层同步原语
- 复杂的线程同步问题:ABA问题、活锁、伪共享 (
false sharing) std::atomic的内存序 (memory_order) 的深刻理解与应用- 实现自定义、生产级的线程安全数据结构 (如
blocking queue,thread pool) std::shared_mutex等高级同步原语的正确使用- 理解并初步实践
lock-free编程思想 (如lock-free stack的简单实现)
复杂度: 8/10 | 影响范围: 9/10 (极致性能、系统正确性) | 解决难度: 8/10
- 说明: 对并发模型的理解达到专家级别,开始探索无锁等高阶技术。
Level 9 - 复杂系统架构、构建与底层交互
- 设计模式的灵活组合与变通应用,以解决大型系统的特定架构问题
Event Loop,Reactor,Proactor等大规模并发服务架构模式的深度设计与实现ECS(Entity-Component-System) 等特定领域架构模式的实践CMake复杂项目管理 (大型依赖、交叉编译、模块化构建)- 链接过程深层问题 (
ODR违规的隐晦场景, 符号版本控制,visibility) LTO(链接时优化),PGO(Profile-Guided Optimization) 的原理与应用- 操作系统底层API (
mmap,shm_open,syscalls) 的高级封装与应用
复杂度: 9/10 | 影响范围: 9/10 (系统整体性能、可维护性、可扩展性) | 解决难度: 9/10
- 说明: 关注整个系统的设计和构建,涉及多方面知识的综合运用,要求开发者具备架构师的视野。
Level 10 - 极致优化、自定义编译器/运行时与前沿技术
- 实现高性能、可扩展的自定义STL兼容
allocator - 开发与调试复杂的、生产级的
lock-free数据结构 (如lock-free queue,lock-free hash map) C++与Assembly的深度混合编程 (手写汇编优化热点路径,intrinsics的极致运用)RDMA,DPDK,XDP/eBPF等内核旁路/零拷贝技术的深度应用LLVM/Clang插件开发,进行代码分析、转换或语言扩展- 构建或集成自定义JIT编译器
复杂度: 10/10 | 影响范围: 10/10 (特定领域的性能突破或功能创新) | 解决难度: 10/10
- 说明: C++金字塔的顶端,通常是特定领域的专家,推动技术边界。
C++ 模板形态学习难度表
| 序号 | 模板形态 (Template Morphology) | 简要描述 | 学习难度 | 最简单行代码示例 (C++) |
|---|---|---|---|---|
| 1 | 泛型编程 (Generic Programming) | 创建类型无关的函数和类,如 STL | 入门 👶 | template<class T> T process(T val) { return val; } |
| 2 | CRTP (Curiously Recurring Template Pattern) | 派生类将自身作为基类的模板参数,用于静态多态和代码复用 | 中等 🤔 | template<class D> struct B{void f(){static_cast<D*>(this)->impl();}}; struct D:B<D>{void impl(){}}; |
| 3 | 静态接口 / 编译期多态 | 通过模板、特化、SFINAE 或 Concepts 在编译期模拟接口,进行检查和绑定 | 中等偏上 🧐 | template<class T> void exec(T& obj) { obj.run_action(); /* assumes T has run_action */ } |
| 4 | 基于策略的设计 (Policy-Based Design) | 将类的行为分解为多个可互换的策略类,通过模板参数组合 | 进阶 🛠️ | template<class Policy> struct Context { Policy p; void act(){p.execute();} }; |
| 5 | 模板元编程 (Template Metaprogramming - TMP) | 在编译期执行计算,生成代码或进行编译时断言 | 高阶 🧠 | template<int N> struct Fact{enum{val=N*Fact<N-1>::val};}; template<> struct Fact<0>{enum{val=1};}; |
| 6 | 表达式模板 (Expression Templates) | 用于优化数值计算,通过构建表达式树的类型延迟计算,消除临时对象 | 专家 🤯 | template<class L,class R> struct Add{L l;R r; auto operator[](int i){return l[i]+r[i];}}; /* auto sum = Add{v1,v2}; */ |
详细说明
1. 泛型编程 (Generic Programming)
- 核心思想: 编写与类型无关的代码
- 应用场景: STL容器、算法、智能指针
- 学习要点: 理解模板基础语法
2. CRTP (Curiously Recurring Template Pattern)
- 核心思想: 基类通过模板参数获得派生类类型,实现静态多态
- 应用场景: 避免虚函数开销、实现接口复用
- 学习要点: 理解静态绑定vs动态绑定
3. 静态接口 / 编译期多态
- 核心思想: 在编译期确定类型和方法调用
- 应用场景: 高性能计算、泛型算法
- 学习要点: SFINAE、Concepts (C++20)
4. 基于策略的设计 (Policy-Based Design)
- 核心思想: 将复杂类的行为分解为多个策略组件
- 应用场景: 智能指针、内存分配器、线程策略
- 学习要点: 组合优于继承的模板应用
5. 模板元编程 (Template Metaprogramming)
- 核心思想: 利用模板在编译期执行计算和代码生成
- 应用场景: 编译期常量计算、类型操作、代码生成
- 学习要点: 递归模板、特化、编译期计算
6. 表达式模板 (Expression Templates)
- 核心思想: 将数学表达式表示为类型,延迟计算以优化性能
- 应用场景: 数值计算库 (如 Eigen、Blitz++)
- 学习要点: 操作符重载、类型推导、延迟求值
学习建议
- 循序渐进: 按照难度顺序学习,每个层次都要熟练掌握
- 实践导向: 多写代码,理解编译器行为
- 源码阅读: 研究 STL、LOKI, Boost 等知名库的实现
- 性能对比: 了解各种技术的性能特点和适用场景
关于 动态规划 - 一个聪明人的“懒人”策略
分解任务: 把大任务分解成小任务。 记录成果: 每个小任务完成后,把结果记下来。 高效利用: 遇到重复的小任务,直接查阅记录,不重复做功。
个人理解:
动态规划 比较简单的判断 就是递归行为. 当然 有些代码 也可以不用递归实现. 但是递归是一个线索. 当你明白 这个代码 类似递归转换出来的迭代. 大概就懂了 动态规划. 当然这个只是我的理解. 懂行的或许还有其他更精简的描述.
应用的技巧与视角,包括:
- 状态的精确定义与选择 (The Art of Defining States):
- 您已经理解了子问题,而“状态”就是用来唯一标识和描述这些子问题的。如何巧妙地定义状态,使其既能包含解决问题所需的所有信息(无后效性),又能让状态空间尽可能小,并且易于转移,这是一门艺术。有时,一个微小的状态定义差异,就会导致解题效率的天壤之别。
- 状态转移方程的推导与模式识别 (Formulating Recurrence Relations):
- 从递归关系到清晰、准确的状态转移方程是核心步骤。理解不同类型DP问题(如序列DP、区间DP、背包DP、树形DP等)常见的状态转移模式,可以帮助我们更快地找到解题思路。
- 边界条件的细致处理 (Handling Base Cases Meticulously):
- 任何递归或迭代过程的正确性都高度依赖于初始条件或边界条件的设置。在动态规划中,这些对应最小规模子问题的解,它们的正确与否直接决定了整个DP解的成败。
- 深刻理解“无后效性” (The No-Aftereffect Property):
- 这是动态规划能够成立的基石之一。它意味着一旦某个阶段的状态确定了,之后决策所依赖的仅仅是当前这个状态本身,而与如何达到这个状态的“历史路径”无关。状态定义必须满足这一点。您提到的递归思想,如果子问题的解一旦算出就是确定的,其实也体现了这一点。
- 问题识别与建模能力 (Identifying and Modeling DP Problems):
- 掌握了DP的原理后,更进一步的挑战是如何识别一个看似无关的问题,判断它是否可以用动态规划解决,并将其抽象和建模成一个DP问题(即定义出合适的状态和状态转移)。这需要大量的练习和经验积累。
- 优化技巧 (Optimization Techniques):
- 比如空间优化(如使用滚动数组将二维DP降至一维空间),或者结合其他数据结构进行优化等。